Function calling
Function calling enables developers to connect language models to external data and systems. You can define a set of functions as tools that the model has access to, and it can use them when appropriate based on the conversation history. You can then execute those functions on the application side, and provide results back to the model.
Learn how to extend the capabilities of OpenAI models through function calling in this guide.
Overview
Many applications require models to call custom functions to trigger actions within the application or interact with external systems.
Here is how you can define a function as a tool for the model to use:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from openai import OpenAI
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"},
"unit": {"type": "string", "enum": ["c", "f"]},
},
"required": ["location", "unit"],
"additionalProperties": False,
},
},
}
]
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "What's the weather like in Paris today?"}],
tools=tools,
)
print(completion.choices[0].message.tool_calls)Here are a few examples where function calling can be useful:
- Fetching data: enable a conversational assistant to retrieve data from internal systems before responding to the user.
- Taking action: allow an assistant to trigger actions based on the conversation, like scheduling meetings or initiating order returns.
- Building rich workflows: allow assistants to execute multi-step workflows, like data extraction pipelines or content personalization.
- Interacting with Application UIs: use function calls to update the user interface based on user input, like rendering a pin on a map or navigating a website.
You can find example use cases in the examples section below.
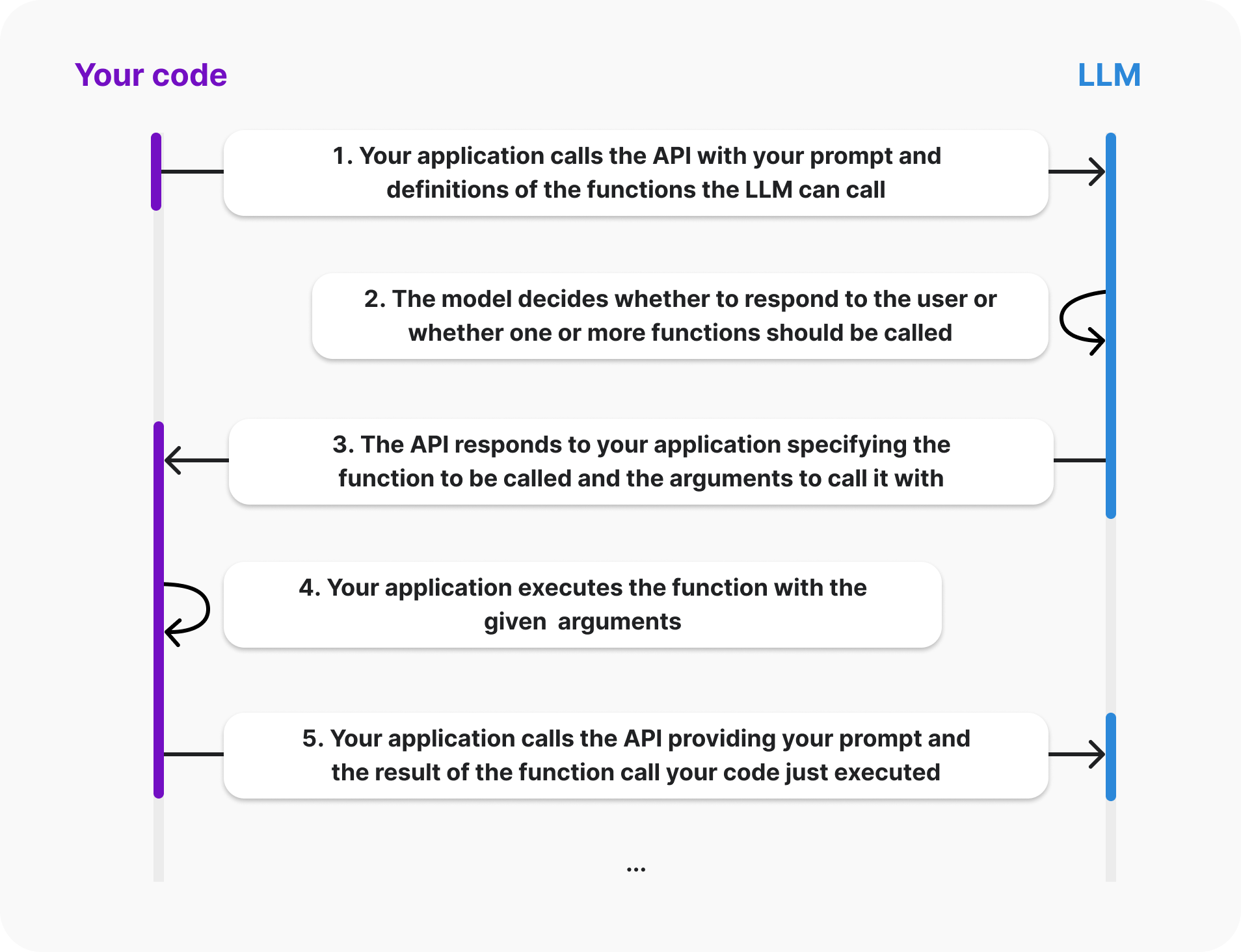
The lifecycle of a function call
When you use the OpenAI API with function calling, the model never actually executes functions itself - instead, it simply generates parameters that can be used to call your function. You are then responsible for handling how the function is executed in your code.
Read our integration guide below for more details on how to handle function calls.
Function calling support
Function calling is supported in the Chat Completions API, Assistants API, Batch API and Realtime API.
This guide focuses on function calling using the Chat Completions API. We have separate guides for function calling using the Assistants API, and for function calling using the Realtime API.
Models supporting function calling
Function calling was introduced with the release of gpt-4-turbo on June 13, 2023. All gpt-* models released after this date support function calling.
Legacy models released before this date were not trained to support function calling.
Integration guide
In this integration guide, we will walk through integrating function calling into an application, taking an order delivery assistant as an example. Rather than requiring users to interact with a form, we can let them ask the assistant for help in natural language.
We will cover how to define functions and instructions, then how to handle model responses and function execution results.
Function definition
The starting point for function calling is choosing a function in your own codebase that you'd like to enable the model to generate arguments for.
For this example, let's imagine you want to allow the model to call the get_delivery_date function in your codebase which accepts an order_id and queries your database to determine the delivery date for a given package.
Your function might look something like the following:
1
2
3
4
5
6
# This is the function that we want the model to be able to call
def get_delivery_date(order_id: str) -> datetime:
# Connect to the database
conn = sqlite3.connect('ecommerce.db')
cursor = conn.cursor()
# ...Now that we know which function we wish to allow the model to call, we will create a “function definition” that describes the function to the model. This definition describes both what the function does (and potentially when it should be called) and what parameters are required to call the function.
The parameters section of your function definition should be described using JSON Schema. If and when the model generates a function call, it will use this information to generate arguments according to your provided schema.
In this example it may look like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID."
}
},
"required": ["order_id"],
"additionalProperties": false
}
}Next we need to provide our function definitions within an array of available “tools” when calling the Chat Completions API.
As always, we will provide an array of “messages”, which could for example contain your prompt or a back and forth conversation between the user and an assistant.
This example shows how you may call the Chat Completions API providing relevant tools and messages for an assistant that handles customer inquiries for a store.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
tools = [
{
"type": "function",
"function": {
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID.",
},
},
"required": ["order_id"],
"additionalProperties": False,
},
}
}
]
messages = [
{
"role": "system",
"content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."
},
{
"role": "user",
"content": "Hi, can you tell me the delivery date for my order?"
}
]
response = openai.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
)Model instructions
While you should define in the function definitions how to call them, we recommend including instructions regarding when to call functions in the system prompt.
For example, you can tell the model when to use the function by saying something like:
"Use the 'get_delivery_date' function when the user asks about their delivery date."
Handling model responses
The model only suggests function calls and generates arguments for the defined functions when appropriate. It is then up to you to decide how your application handles the execution of the functions based on these suggestions.
If the model determines that a function should be called, it will return a tool_calls field in the response, which you can use to determine if the model generated a function call and what the arguments were.
Unless you customize the tool calling behavior, the model will determine when to call functions based on the instructions and conversation.
If the model decides that no function should be called
If the model does not generate a function call, then the response will contain a direct reply to the user as a regular chat completion response.
For example, in this case chat_response.choices[0].message may contain:
1
2
3
4
5
6
chat.completionsMessage(
content='Hi there! I can help with that. Can you please provide your order ID?',
role='assistant',
function_call=None,
tool_calls=None
)In an assistant use case you will typically want to show this response to the user and let them respond to it, in which case you will call the API again (with both the latest responses from the assistant and user appended to the messages).
Let's assume our user responded with their order id, and we sent the following request to the API.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
tools = [
{
"type": "function",
"function": {
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks 'Where is my package'",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The customer's order ID."
}
},
"required": ["order_id"],
"additionalProperties": False
}
}
}
]
messages = []
messages.append({"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."})
messages.append({"role": "user", "content": "Hi, can you tell me the delivery date for my order?"})
messages.append({"role": "assistant", "content": "Hi there! I can help with that. Can you please provide your order ID?"})
messages.append({"role": "user", "content": "i think it is order_12345"})
response = client.chat.completions.create(
model='gpt-4o',
messages=messages,
tools=tools
)If the model generated a function call
If the model generated a function call, it will generate the arguments for the call (based on the parameters definition you provided).
Here is an example response showing this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Choice(
finish_reason='tool_calls',
index=0,
logprobs=None,
message=chat.completionsMessage(
content=None,
role='assistant',
function_call=None,
tool_calls=[
chat.completionsMessageToolCall(
id='call_62136354',
function=Function(
arguments='{"order_id":"order_12345"}',
name='get_delivery_date'),
type='function')
])
)Handling the model response indicating that a function should be called
Assuming the response indicates that a function should be called, your code will now handle this:
1
2
3
4
5
6
7
8
9
10
# Extract the arguments for get_delivery_date
# Note this code assumes we have already determined that the model generated a function call. See below for a more production ready example that shows how to check if the model generated a function call
tool_call = response.choices[0].message.tool_calls[0]
arguments = json.loads(tool_call['function']['arguments'])
order_id = arguments.get('order_id')
# Call the get_delivery_date function with the extracted order_id
delivery_date = get_delivery_date(order_id)Submitting function output
Once the function has been executed in the code, you need to submit the result of the function call back to the model.
This will trigger another model response, taking into account the function call result.
For example, this is how you can commit the result of the function call to a conversation history:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# Simulate the order_id and delivery_date
order_id = "order_12345"
delivery_date = datetime.now()
# Simulate the tool call response
response = {
"choices": [
{
"message": {
"role": "assistant",
"tool_calls": [
{
"id": "call_62136354",
"type": "function",
"function": {
"arguments": "{'order_id': 'order_12345'}",
"name": "get_delivery_date"
}
}
]
}
}
]
}
# Create a message containing the result of the function call
function_call_result_message = {
"role": "tool",
"content": json.dumps({
"order_id": order_id,
"delivery_date": delivery_date.strftime('%Y-%m-%d %H:%M:%S')
}),
"tool_call_id": response['choices'][0]['message']['tool_calls'][0]['id']
}
# Prepare the chat completion call payload
completion_payload = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."},
{"role": "user", "content": "Hi, can you tell me the delivery date for my order?"},
{"role": "assistant", "content": "Hi there! I can help with that. Can you please provide your order ID?"},
{"role": "user", "content": "i think it is order_12345"},
response['choices'][0]['message'],
function_call_result_message
]
}
# Call the OpenAI API's chat completions endpoint to send the tool call result back to the model
response = openai.chat.completions.create(
model=completion_payload["model"],
messages=completion_payload["messages"]
)
# Print the response from the API. In this case it will typically contain a message such as "The delivery date for your order #12345 is xyz. Is there anything else I can help you with?"
print(response)Structured Outputs
In August 2024, we launched Structured Outputs, which ensures that a model's output exactly matches a specified JSON schema.
By default, when using function calling, the API will offer best-effort matching for your parameters, which means that occasionally the model may miss parameters or get their types wrong when using complicated schemas.
You can enable Structured Outputs for function calling by setting the parameter strict: true in your function definition.
When this is enabled, the function arguments generated by the model will be constrained to match the JSON Schema provided in the function definition.
Parallel function calling and Structured Outputs
When the model outputs multiple function calls via parallel function calling, model outputs may not match strict schemas supplied in tools.
In order to ensure strict schema adherence, disable parallel function calls by supplying parallel_tool_calls: false. With this setting, the model will generate one function call at a time.
Why might I not want to turn on Structured Outputs?
The main reasons to not use Structured Outputs are:
- If you need to use some feature of JSON Schema that is not yet supported (learn more), for example recursive schemas.
- If each of your API requests includes a novel schema (i.e. your schemas are not fixed, but are generated on-demand and rarely repeat). The first request with a novel JSON schema will have increased latency as the schema is pre-processed and cached for future generations to constrain the output of the model.
What does Structured Outputs mean for Zero Data Retention?
When Structured Outputs is turned on, schemas provided are not eligible for zero data retention.
Supported schemas
Function calling with Structured Outputs supports a subset of the JSON Schema language.
For more information on supported schemas, see the Structured Outputs guide.
Example
You can use zod in nodeJS and Pydantic in python when using the SDKs to pass your function definitions to the model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from enum import Enum
from typing import Union
from pydantic import BaseModel
import openai
from openai import OpenAI
client = OpenAI()
class GetDeliveryDate(BaseModel):
order_id: str
tools = [openai.pydantic_function_tool(GetDeliveryDate)]
messages = []
messages.append({"role": "system", "content": "You are a helpful customer support assistant. Use the supplied tools to assist the user."})
messages.append({"role": "user", "content": "Hi, can you tell me the delivery date for my order #12345?"})
response = client.beta.chat.completions.create(
model='gpt-4o-2024-08-06',
messages=messages,
tools=tools
)
print(response.choices[0].message.tool_calls[0].function)If you are not using the SDKs, simply add the strict: true parameter to your function definition:
1
2
3
4
5
6
7
8
9
10
11
{
"name": "get_delivery_date",
"description": "Get the delivery date for a customer's order. Call this whenever you need to know the delivery date, for example when a customer asks \\"Where is my package\\"",
"parameters": {
"type": "object",
"properties": {
"order_id": { "type": "string" }
},
"strict": true
}
}Limitations
When you use Structured Outputs with function calling, the model will always follow your exact schema, except in a few circumstances:
- When the model's response is cut off (either due to
max_tokens,stop_tokens, or maximum context length) - When a model refusal happens
- When there is a
content_filterfinish reason
Advanced usage
Streaming tool calls
You can stream tool calls and process function arguments as they are being generated. This is especially useful if you want to display the function arguments in your UI, or if you don't need to wait for the whole function parameters to be generated before executing the function.
To enable streaming tool calls, you can set stream: true in your request.
You can then process the streaming delta and check for any new tool calls delta.
You can find more information on streaming in the API reference.
Here is an example of how you can handle streaming tool calls with the node and python SDKs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
from openai import OpenAI
import json
client = OpenAI()
# Define functions
tools = [
{
"type": "function",
"function": {
"name": "generate_recipe",
"description": "Generate a recipe based on the user's input",
"parameters": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "Title of the recipe.",
},
"ingredients": {
"type": "array",
"items": {"type": "string"},
"description": "List of ingredients required for the recipe.",
},
"instructions": {
"type": "array",
"items": {"type": "string"},
"description": "Step-by-step instructions for the recipe.",
},
},
"required": ["title", "ingredients", "instructions"],
"additionalProperties": False,
},
},
}
]
response_stream = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": (
"You are an expert cook who can help turn any user input into a delicious recipe."
"As soon as the user tells you what they want, use the generate_recipe tool to create a detailed recipe for them."
),
},
{
"role": "user",
"content": "I want to make pancakes for 4.",
},
],
tools=tools,
stream=True,
)
function_arguments = ""
function_name = ""
is_collecting_function_args = False
for part in response_stream:
delta = part.choices[0].delta
finish_reason = part.choices[0].finish_reason
# Process assistant content
if 'content' in delta:
print("Assistant:", delta.content)
if delta.tool_calls:
is_collecting_function_args = True
tool_call = delta.tool_calls[0]
if tool_call.function.name:
function_name = tool_call.function.name
print(f"Function name: '{function_name}'")
# Process function arguments delta
if tool_call.function.arguments:
function_arguments += tool_call.function.arguments
print(f"Arguments: {function_arguments}")
# Process tool call with complete arguments
if finish_reason == "tool_calls" and is_collecting_function_args:
print(f"Function call '{function_name}' is complete.")
args = json.loads(function_arguments)
print("Complete function arguments:")
print(json.dumps(args, indent=2))
# Reset for the next potential function call
function_arguments = ""
function_name = ""
is_collecting_function_args = FalseTool calling behavior
The API supports advanced features such as parallel tool calling and the ability to force tool calls.
To see a practical example of how to force tool calls, see our cookbook:
Edge cases
When you receive a response from the API, if you're not using the SDK, there are a number of edge cases that production code should handle.
In general, the API will return a valid function call, but there are some edge cases when this won't happen:
- When you have specified
max_tokensand the model's response is cut off as a result - When the model's output includes copyrighted material
Also, when you force the model to call a function, the finish_reason will be "stop" instead of "tool_calls".
This is how you can handle these different cases in your code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# Check if the conversation was too long for the context window
if response['choices'][0]['message']['finish_reason'] == "length":
print("Error: The conversation was too long for the context window.")
# Handle the error as needed, e.g., by truncating the conversation or asking for clarification
handle_length_error(response)
# Check if the model's output included copyright material (or similar)
if response['choices'][0]['message']['finish_reason'] == "content_filter":
print("Error: The content was filtered due to policy violations.")
# Handle the error as needed, e.g., by modifying the request or notifying the user
handle_content_filter_error(response)
# Check if the model has made a tool_call. This is the case either if the "finish_reason" is "tool_calls" or if the "finish_reason" is "stop" and our API request had forced a function call
if (response['choices'][0]['message']['finish_reason'] == "tool_calls" or
# This handles the edge case where if we forced the model to call one of our functions, the finish_reason will actually be "stop" instead of "tool_calls"
(our_api_request_forced_a_tool_call and response['choices'][0]['message']['finish_reason'] == "stop")):
# Handle tool call
print("Model made a tool call.")
# Your code to handle tool calls
handle_tool_call(response)
# Else finish_reason is "stop", in which case the model was just responding directly to the user
elif response['choices'][0]['message']['finish_reason'] == "stop":
# Handle the normal stop case
print("Model responded directly to the user.")
# Your code to handle normal responses
handle_normal_response(response)
# Catch any other case, this is unexpected
else:
print("Unexpected finish_reason:", response['choices'][0]['message']['finish_reason'])
# Handle unexpected cases as needed
handle_unexpected_case(response)Token usage
Under the hood, functions are injected into the system message in a syntax the model has been trained on. This means functions count against the model's context limit and are billed as input tokens. If you run into token limits, we suggest limiting the number of functions or the length of the descriptions you provide for function parameters.
It is also possible to use fine-tuning to reduce the number of tokens used if you have many functions defined in your tools specification.
Examples
The OpenAI Cookbook has several end-to-end examples to help you implement function calling.
In our introductory cookbook how to call functions with chat models, we outline two examples of how the models can use function calling. This is a great resource to follow as you get started:
You will also find examples of function definitions for common use cases below.
Best practices
Turn on Structured Outputs by setting strict: "true"
When Structured Outputs is turned on, the arguments generated by the model for function calls will reliably match the JSON Schema that you provide.
If you are not using Structured Outputs, then the structure of arguments is not guaranteed to be correct, so we recommend the use of a validation library like Pydantic to first verify the arguments prior to using them.
Name functions intuitively, with detailed descriptions
If you find the model does not generate calls to the correct functions, you may need to update your function names and descriptions so the model more clearly understands when it should select each function. Avoid using abbreviations or acronyms to shorten function and argument names.
You can also include detailed descriptions for when a function should be called. For complex functions, you should include descriptions for each of the arguments to help the model know what it needs to ask the user to collect that argument.
Name function parameters intuitively, with detailed descriptions
Use clear and descriptive names for function parameters. If applicable, specify the expected format for a parameter in the description (e.g., YYYY-mm-dd or dd/mm/yy for a date).
Consider providing additional information about how and when to call functions in your system message
Providing clear instructions in your system message can significantly improve the model's function calling accuracy. For example, guide the model with instructions like the following:
"Use check_order_status when the user inquires about the status of their order, such as 'Where is my order?' or 'Has my order shipped yet?'".
Provide context for complex scenarios. For example:
"Before scheduling a meeting with schedule_meeting, check the user's calendar for availability using check_availability to avoid conflicts."
Use enums for function arguments when possible
If your use case allows, you can use enums to constrain the possible values for arguments. This can help reduce hallucinations.
For example, if you have an AI assistant that helps with ordering a T-shirt, you likely have a fixed set of sizes for the T-shirt that you might want to constrain the model to choose from. If you want the model to output “s”, “m”, “l”, for small, medium, and large, you could provide those values in an enum, like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"name": "pick_tshirt_size",
"description": "Call this if the user specifies which size t-shirt they want",
"parameters": {
"type": "object",
"properties": {
"size": {
"type": "string",
"enum": ["s", "m", "l"],
"description": "The size of the t-shirt that the user would like to order"
}
},
"required": ["size"],
"additionalProperties": false
}
}If you don't constrain the output, a user may say “large” or “L”, and the model may use these values as a parameter. As your code may expect a specific structure, it's helpful to limit the possible values the model can choose from.
Keep the number of functions low for higher accuracy
We recommend that you use no more than 20 tools in a single API call.
Developers typically see a reduction in the model's ability to select the correct tool once they have between 10-20 tools defined.
If your use case requires the model to be able to pick between a large number of custom functions, you may want to explore fine-tuning (learn more) or break out the tools and group them logically to create a multi-agent system.
Set up evals to act as an aid in prompt engineering your function definitions and system messages
We recommend for non-trivial uses of function calling setting up an evaluation system that allow you to measure how frequently the correct function is called or correct arguments are generated for a wide variety of possible user messages. Learn more about setting up evals on the OpenAI Cookbook.
You can then use these to measure whether adjustments to your function definitions and system messages will improve or hurt your integration.
Fine-tuning may help improve accuracy for function calling
Fine-tuning a model can improve performance at function calling for your use case, especially if you have a large number of functions, or complex, nuanced or similar functions.
See our fine-tuning for function calling cookbook for more information.