延迟优化
本指南涵盖了可用于在各种 LLM 相关使用案例中改善延迟的核心原则集。这些技术来自与广泛的客户和开发人员在生产应用程序上的合作,因此无论您正在构建什么 - 从精细的工作流程到端到端聊天机器人,它们都应该适用。
虽然有许多单独的技术,但我们将它们分为七项原则,旨在代表改善延迟的方法的高级分类法。
最后,我们将通过一个示例来了解如何应用它们。
七项原则
更快地处理令牌
在解决延迟问题时,推理速度可能是首先想到的因素(但您很快就会看到,它远非唯一因素)。这是指 LLM 处理令牌的实际速率,通常以 TPM(每分钟令牌数)或 TPS(每秒令牌数)来衡量。
影响推理速度的主要因素是模型大小 – 较小的模型通常运行得更快(且更便宜),如果使用得当,甚至可以胜过较大的模型。要使用较小的模型保持高质量的性能,您可以探索:
您还可以使用推理优化,例如我们的 Predicted outputs 功能。当您提前知道大部分输出(例如代码编辑任务)时,预测输出可让您显著减少一代的延迟。通过为模型提供预测,LLM 可以更多地关注实际变化,而不是关注保持不变的内容。
生成更少的令牌
使用 LLM 时,生成令牌几乎总是延迟最高的步骤:作为一般的启发式方法,削减 50% 的输出令牌可能会减少 ~50% 的延迟。减小输出大小的方式将取决于输出类型:
如果要生成自然语言,只需要求模型更简洁(“少于 20 个单词”或“非常简短”)可能会有所帮助。您还可以使用少量镜头示例和/或微调来教给模型更短的响应。
如果要生成结构化输出,请尽可能减少输出语法:缩短函数名称、省略命名参数、合并参数等。
最后,虽然不常见,但您也可以使用 或 提前结束您的一代。max_tokensstop_tokens
永远记住:输出令牌削减是获得(毫秒)秒!
使用更少的输入令牌
虽然减少输入令牌的数量确实可以降低延迟,但这通常不是一个重要因素——减少 50% 的提示可能只会导致 1-5% 的延迟改善。除非你正在处理真正巨大的上下文大小(文档、图像),否则你可能想把精力花在其他地方。
话虽如此,如果您正在处理大量上下文(或者您打算压缩每一点性能并且已经用尽了所有其他选项),则可以使用以下技术来减少输入令牌:
- 微调模型,以取代冗长的说明/示例的需求。
- 过滤上下文输入,例如修剪 RAG 结果、清理 HTML 等。
- 通过在提示中稍后放置动态部分(例如 RAG 结果、历史记录等)来最大化共享提示前缀。这使您的请求对 KV 缓存更友好(大多数 LLM 提供商都使用),并且意味着每个请求处理的输入令牌更少。
减少请求
每次发出请求时,都会产生一些往返延迟 – 这可能会开始累积。
如果您有 LLM 要执行的连续步骤,请考虑将它们放在单个提示中,并将它们全部放在一个响应中,而不是每个步骤触发一个请求。您将避免额外的往返延迟,并可能降低处理多个响应的复杂性。
执行此操作的一种方法是在组合提示的枚举列表中收集您的步骤,然后请求模型返回 JSON 中命名字段中的结果。这样你就可以轻松解析和引用每个结果!
并行化
使用 LLM 执行多个步骤时,并行化可能非常强大。
如果这些步骤不是严格顺序的,则可以将它们拆分为并行调用。两件衬衫的干燥时间与一件一样长。
但是,如果这些步骤是严格连续的,您仍然可以利用推测执行。这对于一个结果比其他结果更有可能的分类步骤(例如节制)特别有效。
- 同时开始步骤1和步骤2(例如输入审核和故事生成)
- 验证步骤 1 的结果
- 如果结果不是预期的,请取消步骤 2(并在必要时重试)
如果您对第 1 步的猜测是正确的,那么您基本上必须在零额外延迟的情况下运行它!
减少用户的等待时间
等待和观察进展之间存在巨大差异 - 确保您的用户体验后者。以下是一些技巧:
- 流式处理:最有效的方法,因为它将等待时间缩短到一秒或更短。(如果你在每个回复完成之前什么都看不到,ChatGPT 的感觉会很不一样。
- 分块:如果您的输出在显示给用户之前需要进一步处理(审核、翻译),请考虑分块处理,而不是一次全部处理。为此,您可以流式传输到您的后端,然后将处理后的 chunk 发送到您的前端。
- 显示您的步骤:如果您执行多个步骤或使用工具,请向用户显示此步骤。您可以展示的真实进展越多越好。
- 加载状态:微调器和进度条大有帮助。
请注意,虽然显示您的步骤和具有加载状态,但大部分都有一个 心理效应,流和分块确实确实降低了整体 考虑 App + 用户系统的延迟:用户将读完响应 早。
不要默认为 LLM
LLM 非常强大且用途广泛,因此有时用于更快的经典方法更合适的情况。识别此类情况可能会让您显著减少延迟。请考虑以下示例:
- 硬编码:如果您的输出受到高度约束,则可能不需要 LLM 来生成它。操作确认、拒绝消息和标准输入请求都是硬编码的好候选者。(您甚至可以使用古老的方法,为每个方法想出一些变体。
- 预计算:如果您的输入受到限制(例如类别选择),您可以提前生成多个响应,并确保永远不会向用户显示相同的响应两次。
- 利用 UI:汇总的指标、报告或搜索结果有时使用经典的定制 UI 组件而不是 LLM 生成的文本来更好地传达。
- 传统优化技术:LLM 应用程序仍然是一个应用程序;二进制搜索、缓存、哈希映射和运行时复杂性在 LLM 的世界中仍然很有用。
例
现在,我们来看一个示例应用程序,确定潜在的延迟优化,并提出一些解决方案!
我们将分析一个受真实生产应用程序启发的假想客户服务机器人的架构和提示。架构和提示部分设置了阶段,分析和优化部分将介绍延迟优化过程。
架构和提示
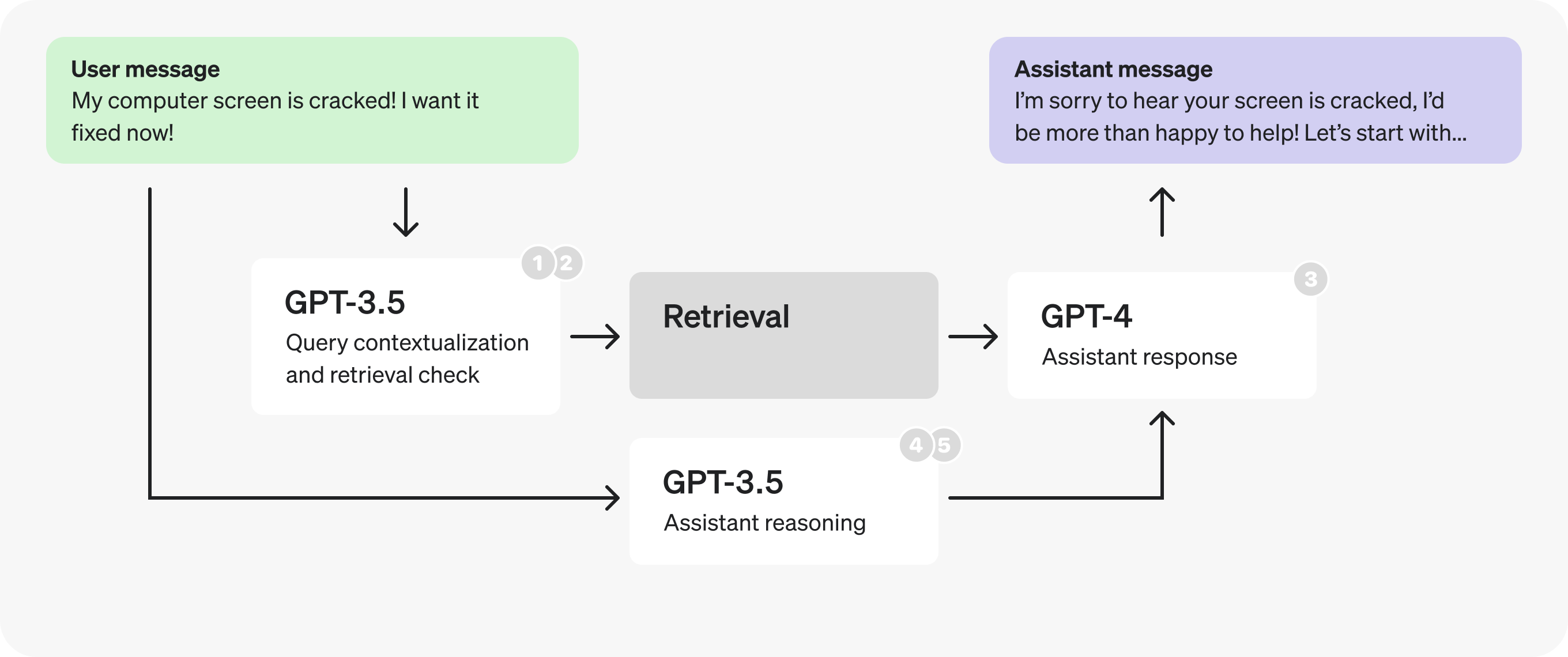
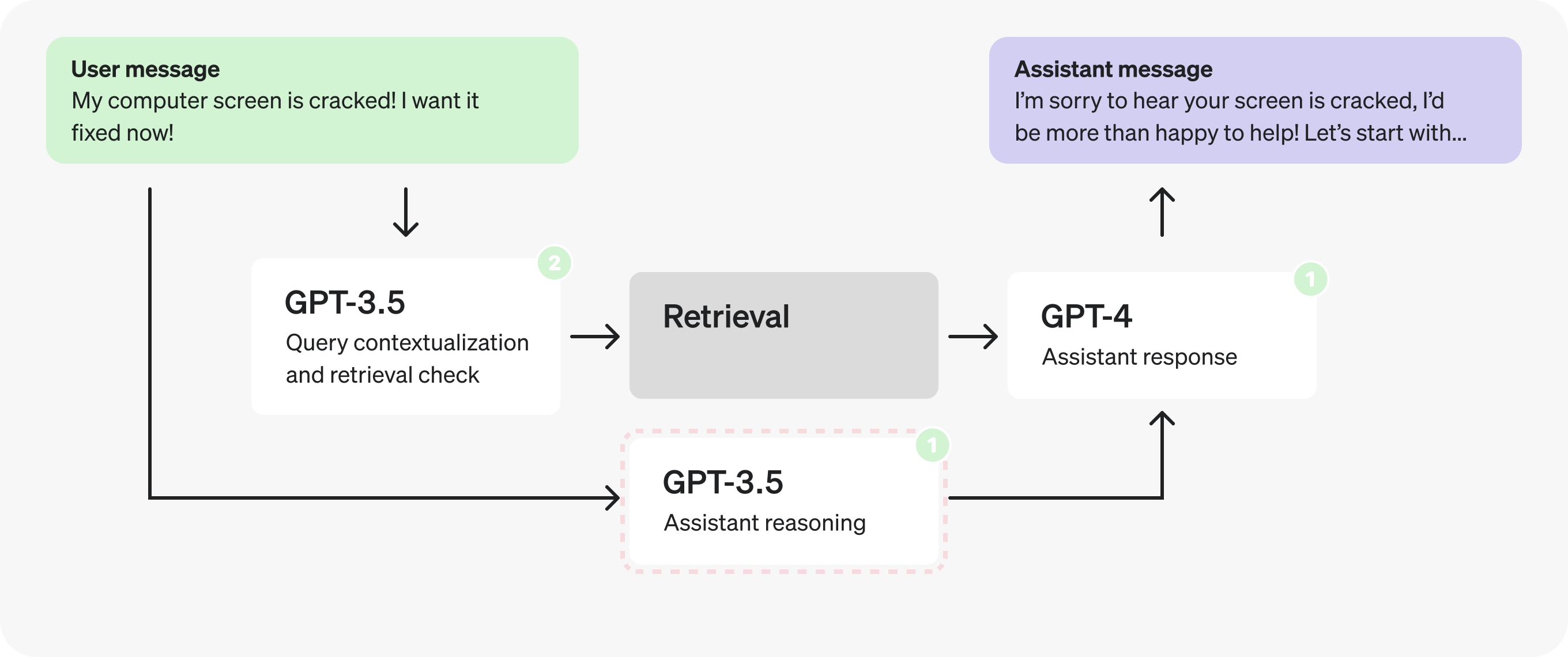
以下是假设的客户服务机器人的初始架构。这就是我们将要做出的更改。
概括地说,图表流描述了以下过程:
- 用户发送消息作为正在进行的对话的一部分。
- 最后一条消息将转换为自包含查询(请参阅提示符中的示例)。
- 我们确定是否需要其他 (检索) 信息来响应该查询。
- 执行检索,生成搜索结果。
- 助手对用户的查询和搜索结果进行推理,并生成响应。
- 响应将发送回用户。
以下是图的每个部分中使用的提示。虽然它们仍然只是假设和简化的,但它们的编写结构和措辞与你在生产应用程序中找到的相同。
分析和优化
第 1 部分:查看检索提示
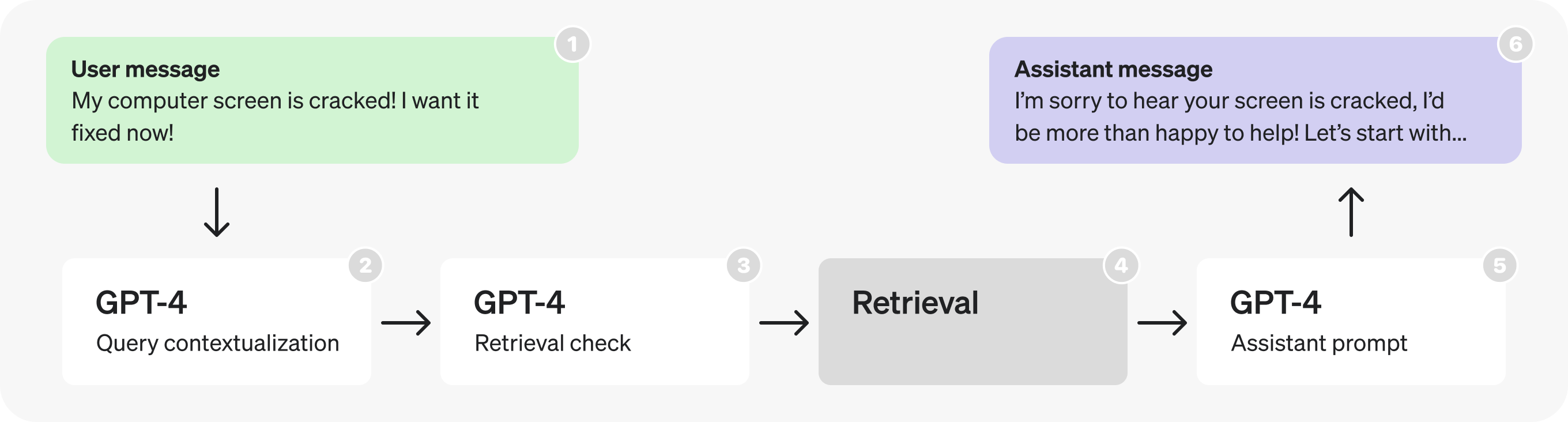
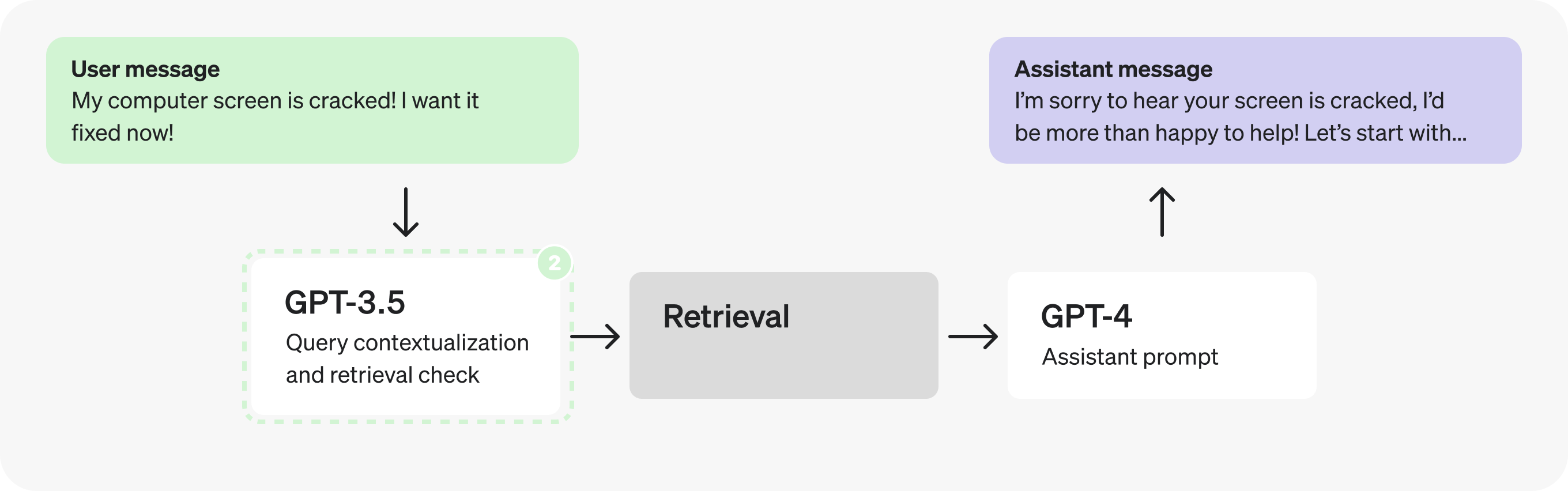
从架构来看,首先突出的是连续的 GPT-4 调用——这些暗示了潜在的低效率,并且通常可以用单个调用或并行调用来代替。
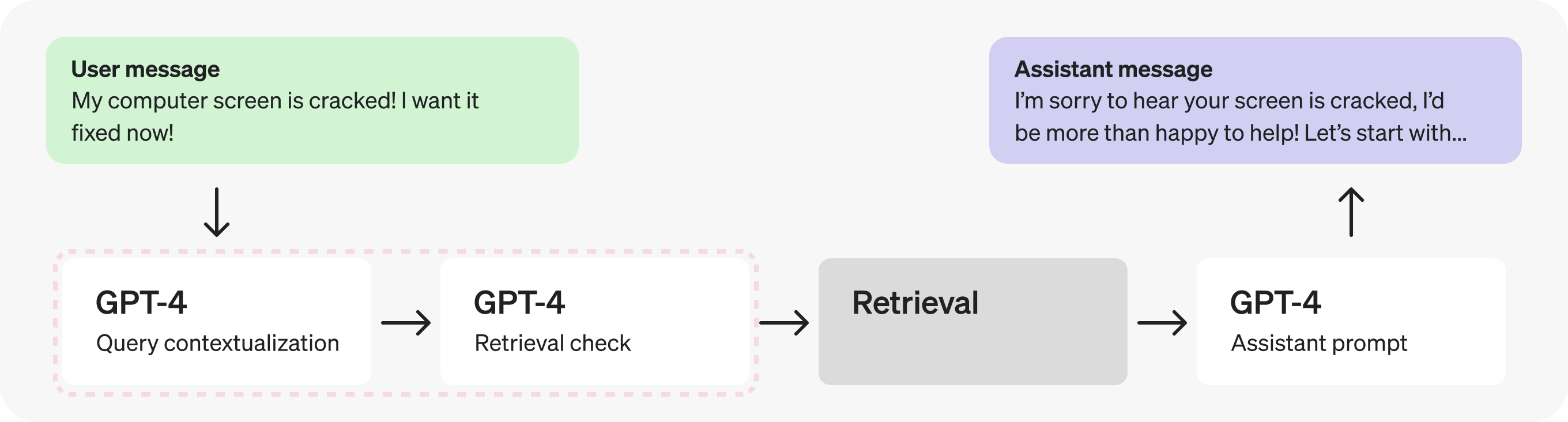
在这种情况下,由于检索检查需要上下文化查询,因此让我们将它们合并到一个提示中,以减少请求的请求。
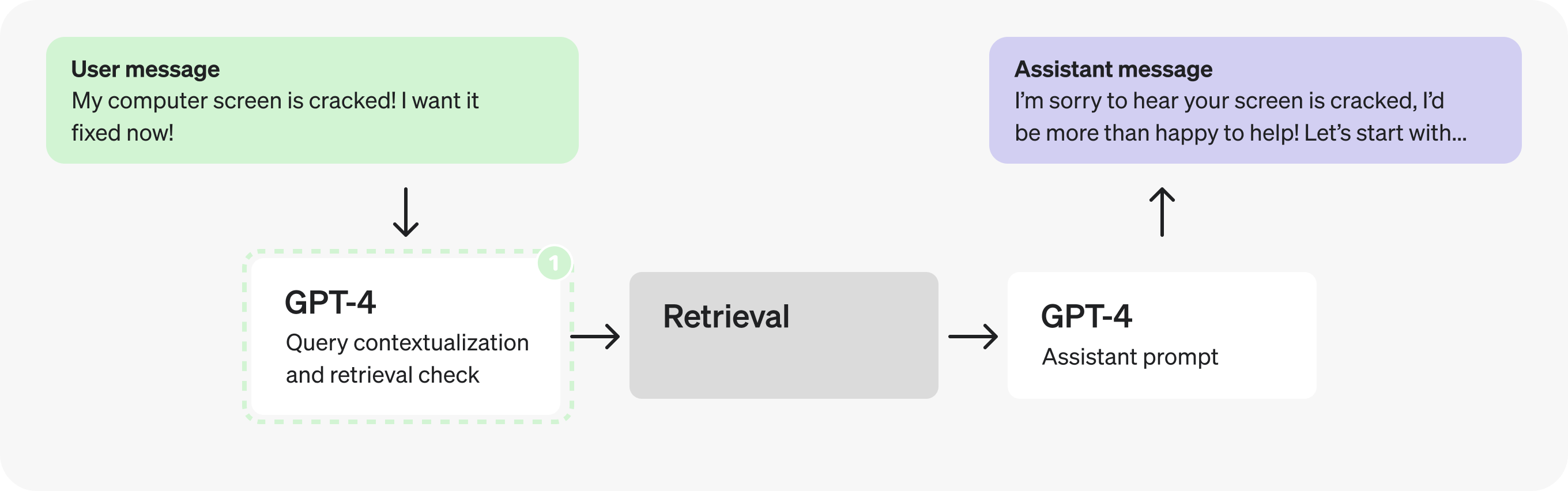
实际上,添加上下文和确定是否检索是非常简单且定义明确的任务,因此我们可以使用更小、经过微调的模型来代替。切换到 GPT-3.5 将使我们能够更快地处理令牌。
第 2 部分:分析助手提示
现在,让我们将注意力转移到 Assistant 提示符上。在填充 JSON 字段时,似乎有许多不同的步骤发生 – 这可能表明存在并行化的机会。
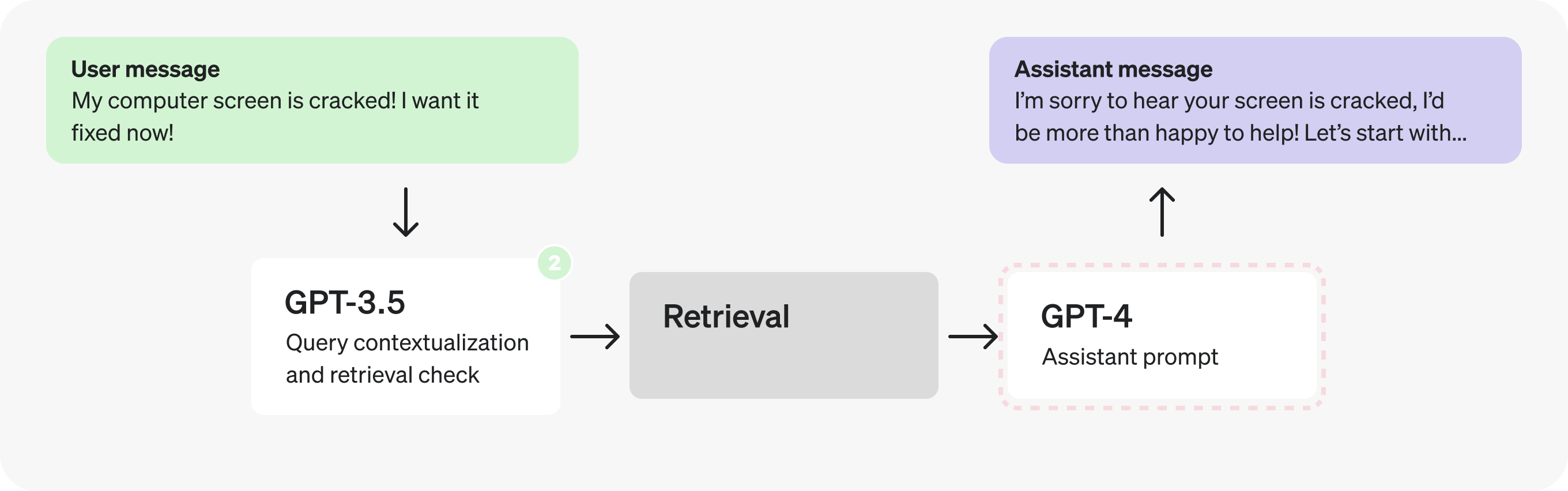
但是,让我们假设我们已经运行了一些测试,并发现在 JSON 中拆分推理步骤会产生更糟糕的响应,因此我们需要探索不同的解决方案。
我们可以使用微调的 GPT-3.5 而不是 GPT-4 吗?也许吧——但总的来说,助手的开放式回答最好留给 GPT-4,这样它就可以更好地处理更多情况。话虽如此,从推理步骤本身来看,它们可能并不都需要 GPT-4 级别的推理来产生。定义明确、范围有限的性质使它们成为微调的良好潜在候选者。
1
2
3
4
5
6
7
8
9
10
11
{
"message_is_conversation_continuation": "True", // <-
"number_of_messages_in_conversation_so_far": "1", // <-
"user_sentiment": "Aggravated", // <-
"query_type": "Hardware Issue", // <-
"response_tone": "Validating and solution-oriented", // <-
"response_requirements": "Propose options for repair or replacement.", // <-
"user_requesting_to_talk_to_human": "False", // <-
"enough_information_in_context": "True" // <-
"response": "..." // X -- benefits from GPT-4
}这为权衡提供了可能性。我们是将其作为完全由 GPT-4 生成的单个请求,还是将其拆分为两个连续的请求,并使用 GPT-3.5 进行除最终响应之外的所有响应?我们有一个原则冲突的情况:第一个选项允许我们发出更少的请求,但第二个选项可能让我们更快地处理令牌。
与许多优化权衡一样,答案将取决于细节。例如:
- 字段中的标记与其他字段的比例。
response - 处理大多数字段的速度会加快,平均延迟会降低。
- 执行 2 个请求而不是 1 个请求的平均延迟增加。
结论会因情况而异,做出判断的最佳方法是用生产示例来检验。在这种情况下,让我们假设测试表明将提示一分为二以更快地处理令牌是有利的。
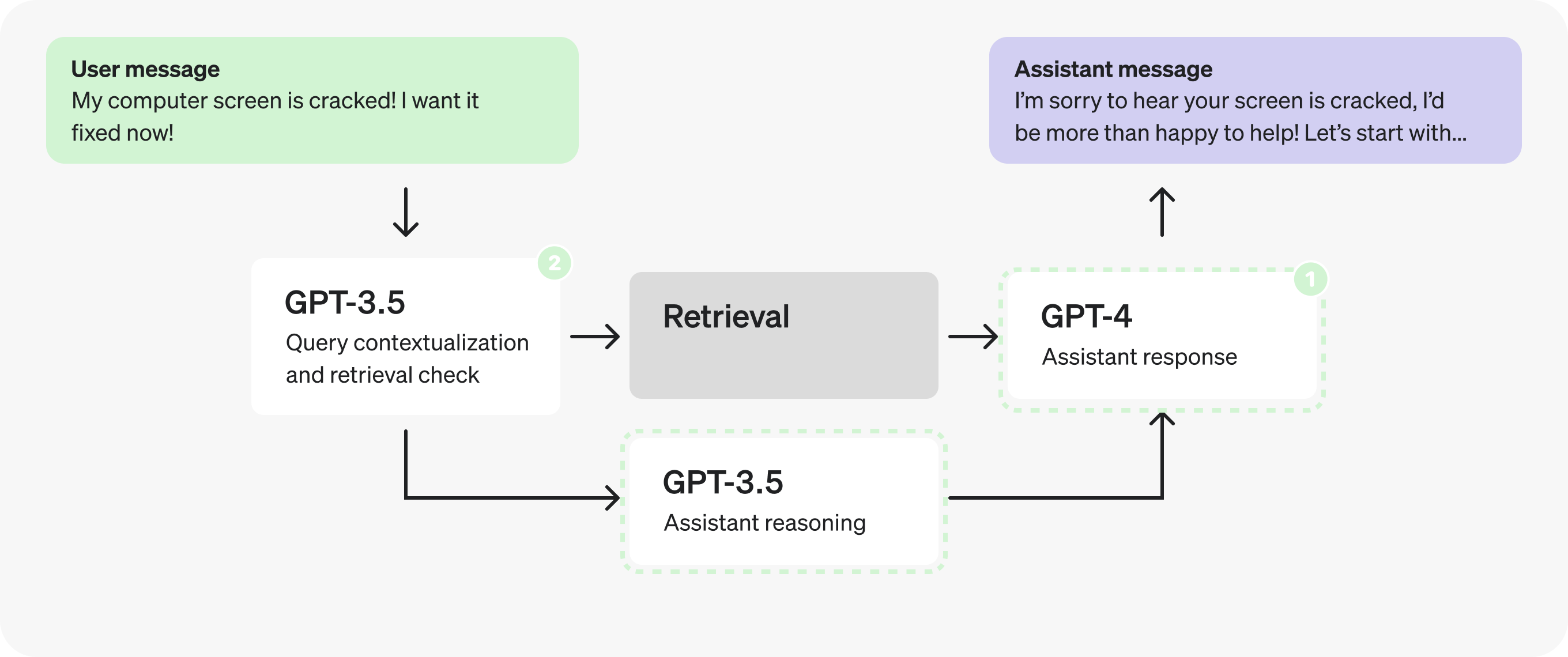
注意:我们将在第二个 Prompt 中将 and 分组在一起,以避免将检索到的上下文传递给两个新 Prompt。responseenough_information_in_context
事实上,既然推理提示不依赖于检索到的上下文,我们可以在检索提示的同时并行化并触发它。
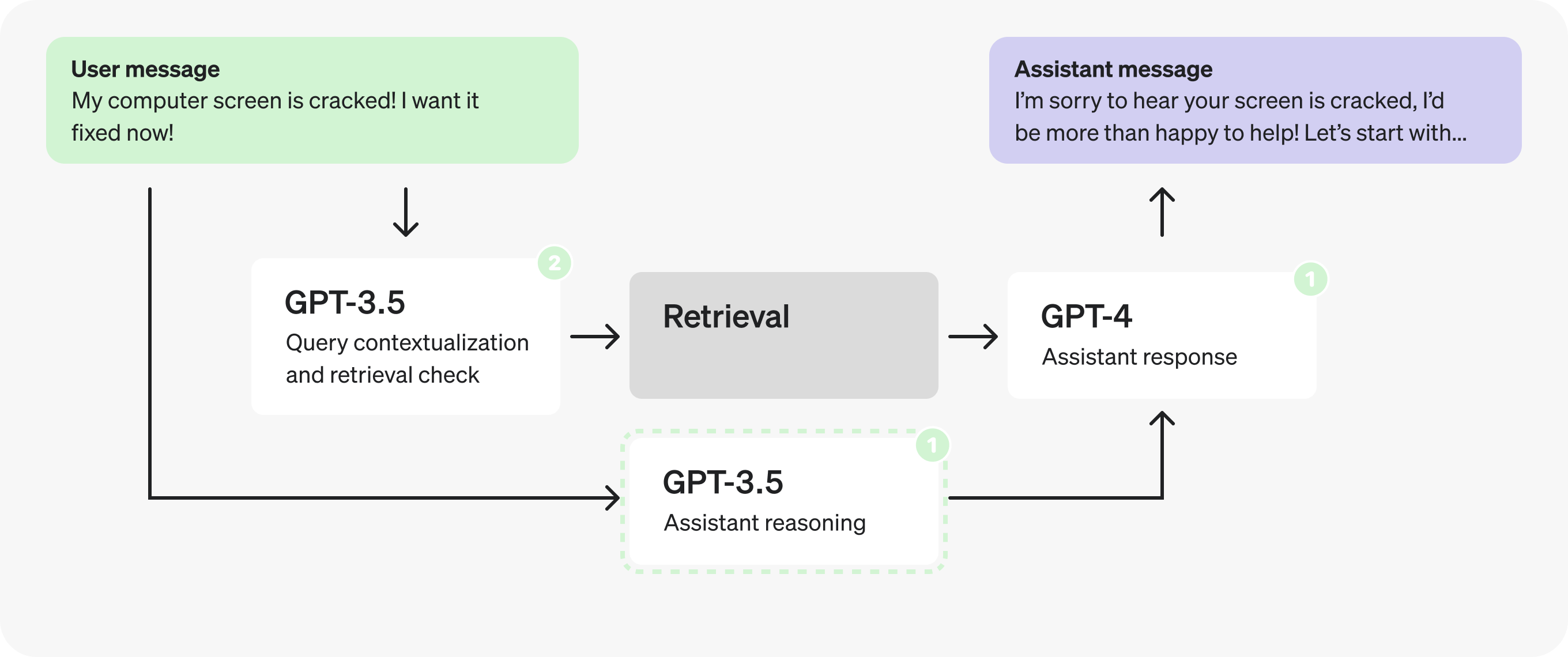
第 3 部分:优化结构化输出
让我们再看一下推理提示。
仔细查看推理 JSON,您可能会注意到字段名称本身很长。
1
2
3
4
5
6
7
8
9
{
"message_is_conversation_continuation": "True", // <-
"number_of_messages_in_conversation_so_far": "1", // <-
"user_sentiment": "Aggravated", // <-
"query_type": "Hardware Issue", // <-
"response_tone": "Validating and solution-oriented", // <-
"response_requirements": "Propose options for repair or replacement.", // <-
"user_requesting_to_talk_to_human": "False", // <-
}通过缩短它们并将解释移至评论,我们可以生成更少的标记。
1
2
3
4
5
6
7
8
9
{
"cont": "True", // whether last message is a continuation
"n_msg": "1", // number of messages in the continued conversation
"tone_in": "Aggravated", // sentiment of user query
"type": "Hardware Issue", // type of the user query
"tone_out": "Validating and solution-oriented", // desired tone for response
"reqs": "Propose options for repair or replacement.", // response requirements
"human": "False", // whether user is expressing want to talk to human
}
这个小的更改删除了 19 个输出标记。虽然使用 GPT-3.5 这可能只会导致几毫秒的改进,但使用 GPT-4 可能会缩短多达一秒。

但是,您可能会想象这会对较大的模型输出产生相当大的影响。
我们可以更进一步,对 JSON 字段使用单个聊天器,或者将所有内容放在一个数组中,但这可能会开始损害我们的响应质量。再次获得信息的最佳方式是通过测试。
总结 示例
让我们回顾一下我们为客户服务机器人示例实施的优化: